Difference between revisions of "Logistic distribution"
m (→See Also) |
m (Cum and CumInv in 5.2 don't require adding densities library) |
||
| (7 intermediate revisions by the same user not shown) | |||
| Line 1: | Line 1: | ||
| − | [[ | + | [[category:Continuous distributions]] |
| + | [[category:Unbounded distributions]] | ||
| + | [[category:Unimodal distributions]] | ||
| + | [[category:Univariate distributions]] | ||
| + | |||
{{ReleaseBar}} | {{ReleaseBar}} | ||
| Line 9: | Line 13: | ||
=== Logistic( mean'', scale, over'' ) === | === Logistic( mean'', scale, over'' ) === | ||
The distribution function. Use to define a quantity as being logistically-distributed. | The distribution function. Use to define a quantity as being logistically-distributed. | ||
| − | === Dens{{Release||5.1|_}}Logistic(x, mean'', scale'')=== | + | === <div id="DensLogistic">Dens{{Release||5.1|_}}Logistic(x, mean'', scale'')</div>=== |
{{Release||5.1|To use, add the [[Distribution Densities Library]] to your model.}}{{Release|5.2||''(New as a built-in function in [[Analytica 5.2]])''}} | {{Release||5.1|To use, add the [[Distribution Densities Library]] to your model.}}{{Release|5.2||''(New as a built-in function in [[Analytica 5.2]])''}} | ||
The probability density at «x» for a logistic distribution with «mean» and «scale». Equal to | The probability density at «x» for a logistic distribution with «mean» and «scale». Equal to | ||
:<math>p(x) = {\eta \over {s ( 1 + \eta)^2} }</math>, where <math>\eta = \exp\left(-{ {x-mean}\over {scale}}\right)</math> | :<math>p(x) = {\eta \over {s ( 1 + \eta)^2} }</math>, where <math>\eta = \exp\left(-{ {x-mean}\over {scale}}\right)</math> | ||
| − | === CumLogistic( x, mean'', scale'' ) === | + | === <div id="CumLogistic">CumLogistic( x, mean'', scale'' )</div> === |
| − | To use, add the [[Distribution Densities Library]] to your model. | + | {{Release||5.1|To use, add the [[Distribution Densities Library]] to your model.}} |
The cumulative density function, describing the probability of being less than or equal to «x». Given by | The cumulative density function, describing the probability of being less than or equal to «x». Given by | ||
| Line 22: | Line 26: | ||
</math> | </math> | ||
| − | === CumLogisticInv( p, mean'', scale'' ) === | + | === <div id="CumLogisticInv">CumLogisticInv( p, mean'', scale'' )</div> === |
| − | To use, add the [[Distribution Densities Library]] to your model. | + | {{Release||5.1|To use, add the [[Distribution Densities Library]] to your model.}} |
The inverse cumulative probability function, also know as the quantile function. Returns the value for which has a «p» probability of being greater than or equal to the true value. | The inverse cumulative probability function, also know as the quantile function. Returns the value for which has a «p» probability of being greater than or equal to the true value. | ||
| Line 30: | Line 34: | ||
</math> | </math> | ||
| − | == Parameters == | + | === Parameters === |
* «mean»: The mean, which for the logistic distribution is also the mode and median. Any real number. | * «mean»: The mean, which for the logistic distribution is also the mode and median. Any real number. | ||
* «scale»: optional, defaults to 1. Must be positive. | * «scale»: optional, defaults to 1. Must be positive. | ||
| Line 43: | Line 47: | ||
* [[Median]] = «mean» | * [[Median]] = «mean» | ||
* [[Mode]] = «mean» | * [[Mode]] = «mean» | ||
| + | |||
| + | == Parameter Estimation == | ||
| + | The parameters of the distribution can be estimated using: | ||
| + | :<code>«mean» := [[Mean]](X, I) </code> | ||
| + | :<code>«scale» := [[Sqrt]](3*[[Variance]](X, I))/[[Pi]]</code> | ||
== Applications == | == Applications == | ||
| Line 52: | Line 61: | ||
has a simple linear form. This linear form lends itself to linear regression techniques for estimating the distribution — for example, from clinical trial data. | has a simple linear form. This linear form lends itself to linear regression techniques for estimating the distribution — for example, from clinical trial data. | ||
| − | == | + | ==Examples== |
| − | + | :<code>Logistic(17, 10)</code> → [[Image:Logistic Distribution.jpg]] | |
| − | :<code> | ||
| − | |||
| − | |||
| − | |||
| − | |||
== See Also == | == See Also == | ||
* [[LogisticRegression]] | * [[LogisticRegression]] | ||
| − | * [[Mean]], [[Variance]], [[Skewness], [[Kurtosis]] | + | * [[Mean]], [[Variance]], [[Skewness]], [[Kurtosis]] |
| − | * [[Keelin]] | + | * A 2-term [[Keelin]] distribution is a [[Logistic]] distribution. |
* [[Distribution Densities Library]] | * [[Distribution Densities Library]] | ||
Latest revision as of 21:01, 9 October 2018
| Release: |
4.6 • 5.0 • 5.1 • 5.2 • 5.3 • 5.4 • 6.0 • 6.1 • 6.2 • 6.3 • 6.4 • 6.5 |
|---|
The logistic distribution describes a continuous, symmetric, smooth, uni-modal distribution with tails that are heavier than the normal distribution.
Logistic(17, 10) → 
Functions
Logistic( mean, scale, over )
The distribution function. Use to define a quantity as being logistically-distributed.
DensLogistic(x, mean, scale)
(New as a built-in function in Analytica 5.2)
The probability density at «x» for a logistic distribution with «mean» and «scale». Equal to
- [math]\displaystyle{ p(x) = {\eta \over {s ( 1 + \eta)^2} } }[/math], where [math]\displaystyle{ \eta = \exp\left(-{ {x-mean}\over {scale}}\right) }[/math]
CumLogistic( x, mean, scale )
The cumulative density function, describing the probability of being less than or equal to «x». Given by
- [math]\displaystyle{ F(x)=\frac{1}{1+exp \Big(-\frac{(x-mean)}{scale}\Big)} }[/math]
CumLogisticInv( p, mean, scale )
The inverse cumulative probability function, also know as the quantile function. Returns the value for which has a «p» probability of being greater than or equal to the true value.
- [math]\displaystyle{ F^{-1}(p) = «mean» - «scale» \ln\left({1-p}\over p\right) }[/math]
Parameters
- «mean»: The mean, which for the logistic distribution is also the mode and median. Any real number.
- «scale»: optional, defaults to 1. Must be positive.
- «over»: optional. A list of indexes to independently sample over.
Statistics
Theoretical (i.e., in the absence of sampling error) for the logistic distribution are as follows.
- Mean = «mean»
- Variance = [math]\displaystyle{ {\pi^2}\over 3 «scale» }[/math]
- Skewness = 0
- Kurtosis = 6/5
- Median = «mean»
- Mode = «mean»
Parameter Estimation
The parameters of the distribution can be estimated using:
Applications
LogisticRegression
The logistic distribution is particularly convenient for determining dependent probabilities using linear regression techniques, where the probability of a binomial event depends monotonically on a continuous variable x. For example, in a toxicology assay, x may be the dosage of a toxin, and p(x) the probability of death for an animal exposed to that dosage. Using p(x) = F(x), the logit of p, given by
has a simple linear form. This linear form lends itself to linear regression techniques for estimating the distribution — for example, from clinical trial data.
Examples
Logistic(17, 10)→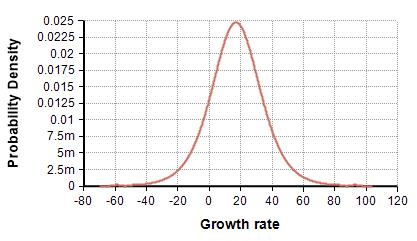
See Also
- LogisticRegression
- Mean, Variance, Skewness, Kurtosis
- A 2-term Keelin distribution is a Logistic distribution.
- Distribution Densities Library
Enable comment auto-refresher